An AI that Predicts Video Game ESRB Ratings
A machine learning model, created by Jonah Yang and Isabelle Hu. Given the year, genre, and platform of a game, it can predict the video game's ESRB rating.

Project Sections
Our Vision
Our initial goal was to accurately predict the age range of a certain game, a certain time period, a certain genre, or of all three. However, due to a lack of solid data, we had to compromise. Now, we show the ESRB ratings for games and genres.
Cleaning and Processing Data
The first thing when developing any machine learning is to get the data and clean it. To do this, we dropped the rows and columns that were useless and/or empty. Next, we converted Genre and Platform (which are our inputs) and ESRB Rating (which is our output) from strings into numbers. Then we balanced the dataset, then divided it into training and testing. After this process, we were ready to feed the data into our model.
K-Nearest Neighbors
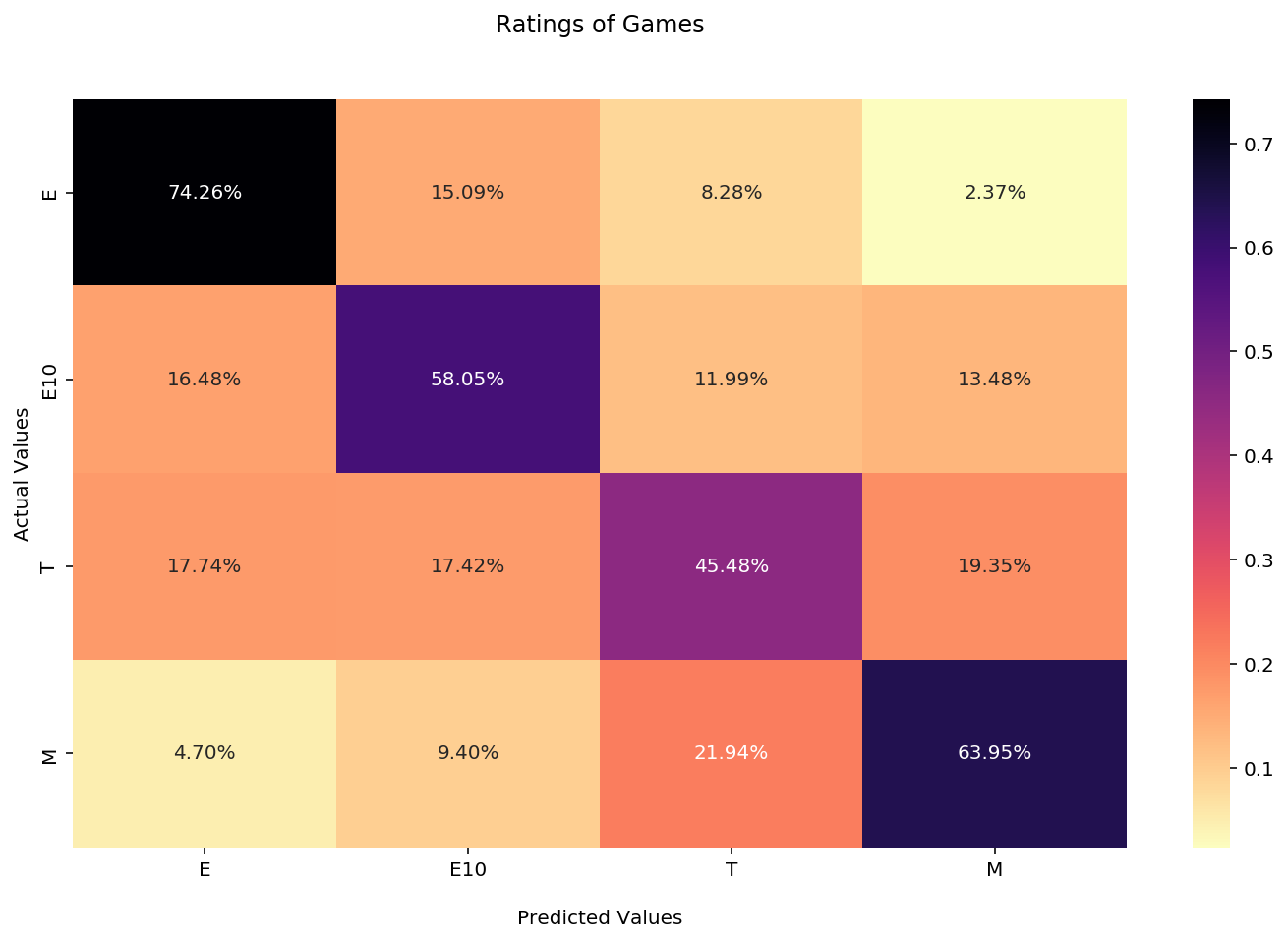
Our machine learning model uses KNN, or K-Nearest Neighbors. This works by looking at a datapoint’s K nearest neighbors to define it. For example, if all the nearest neighbors of the datapoint are E-rated, the datapoint is very likely also to be E-rated. K can be set by the user, defaulting to 5. For our model, we used the value of 7.
Visualization
HEATMAPS (jonah)
Our Goal
Processing Data
The first thing we did with the data was to clean it. We deleted all columns but the Name, ESRB Rating, Genre, Developer, Year, and Platform because many of the other columns were either empty or useless.
Next, we dropped the duplicates, the rows with N/A and NaN, and the ESRB ratings that are too infrequent to be used.
Then, we used custom hash functions to convert the ESRB Rating, Genre and Platform from strings to integers.
Finally, we balanced the dataset because some ESRB ratings were overrepresented. Then, we divided into training and testing.
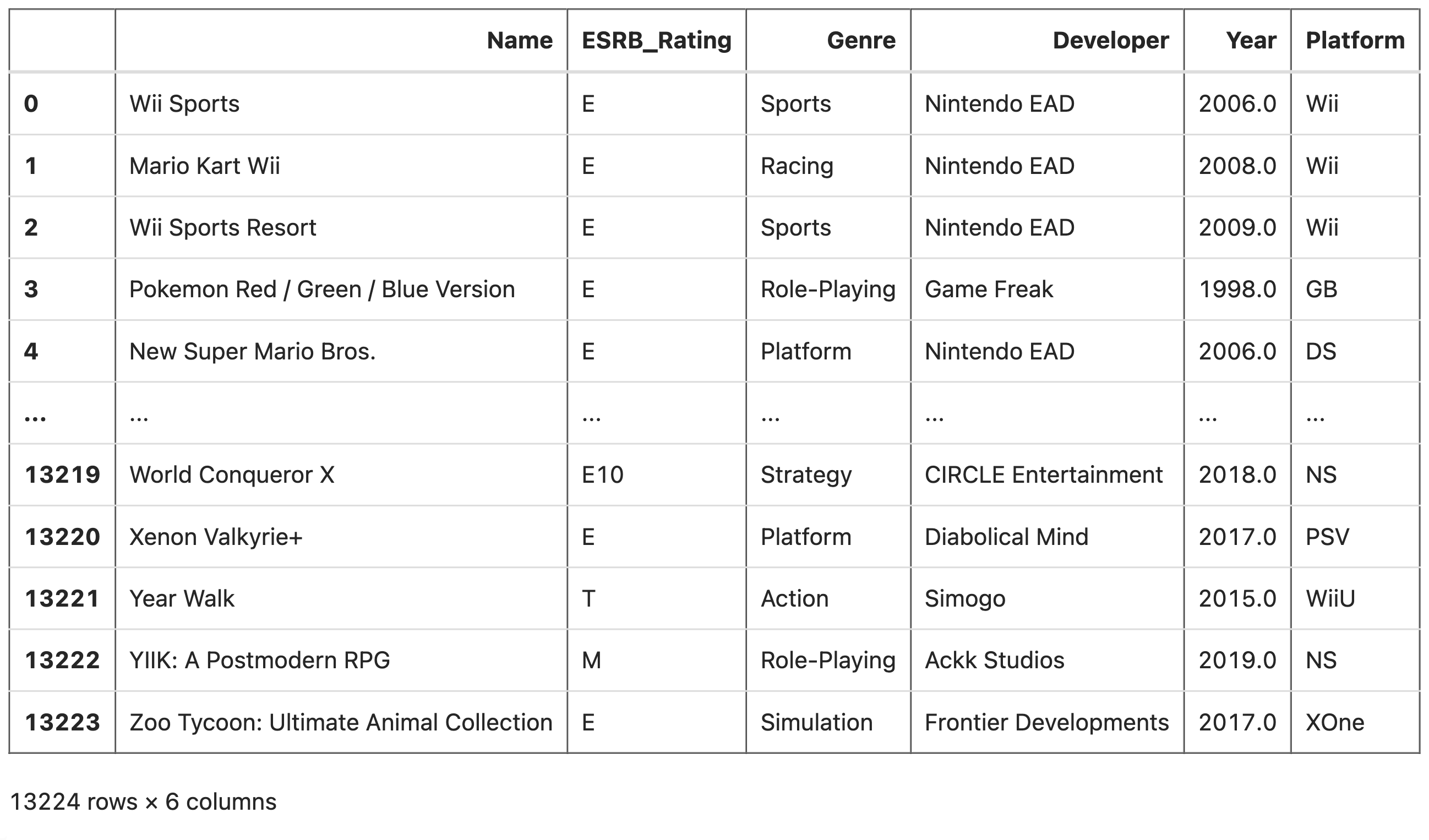
A screenshot of our dataset.
Our Work
Assorted heatmaps
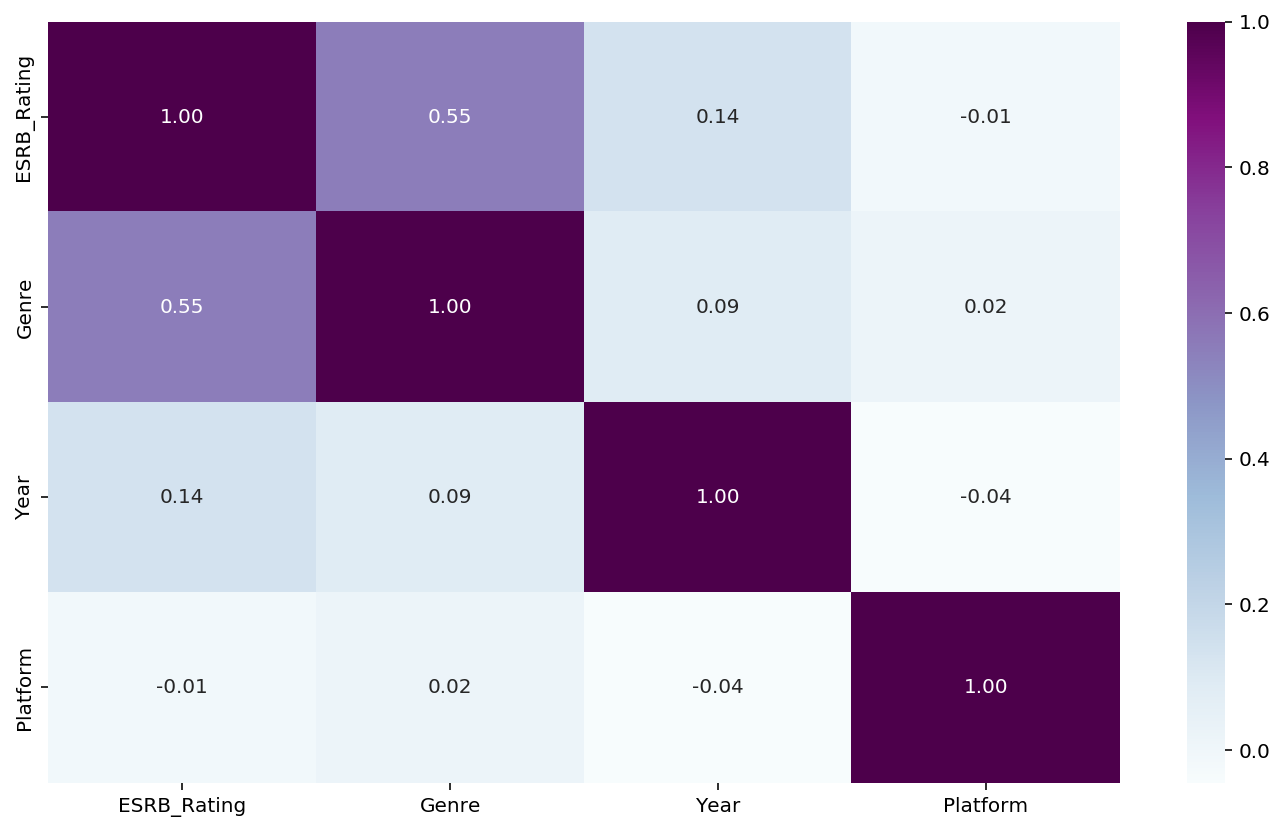
This is a heatmap to show correlation between the major factors of a video game (Platform, Year, Genre, ESRB Rating). We chose this visual because of our goal of taking success rate based on genre, age range, and year it was introduced to the public.